
Python Regular Expressions - Cheat Sheet
- Valeria Aynbinder
- Coding
- 16 Oct, 2024
Many code examples + useful tips. Bonus added to the end of the post.
Regular expressions is an extremely useful tool, and like any developer, I use it a lot when working with texts. Since I always forget the syntax related to regular expressions, I thought creating a simple cheat sheet might help me and maybe others as well :)
Python’s re most useful methods and differences between them
Reminder: re module implements Regular Expressions functionality in Python.

re.matchmatches a regex pattern to the beginning of a string (returned: re.Match)
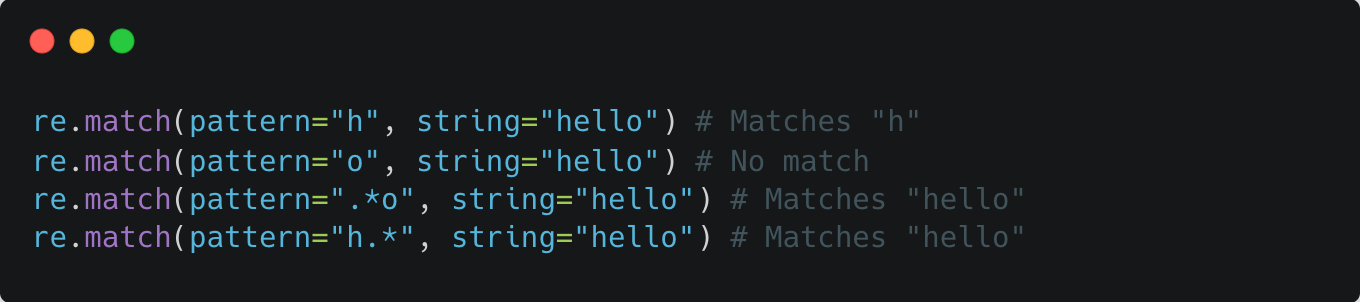
re.fullmatchmatches a regex pattern to the whole string (returned: re.Match)
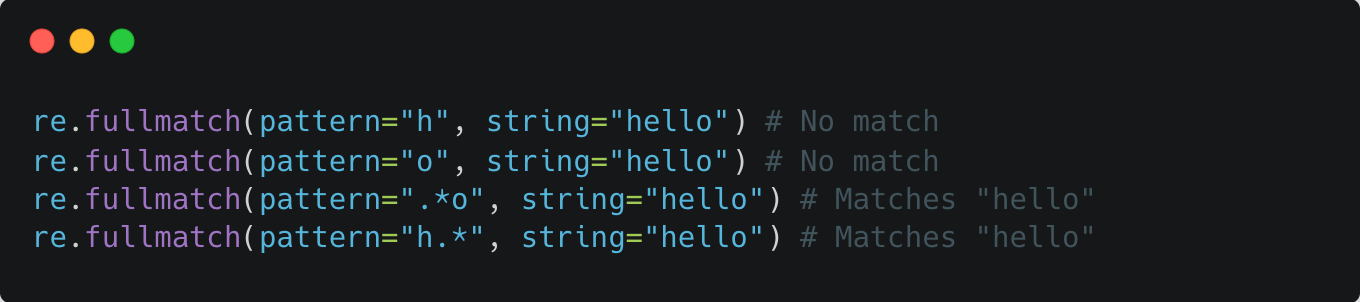
re.searchsearches a string for the presence of a regex pattern (returned: re.Match )
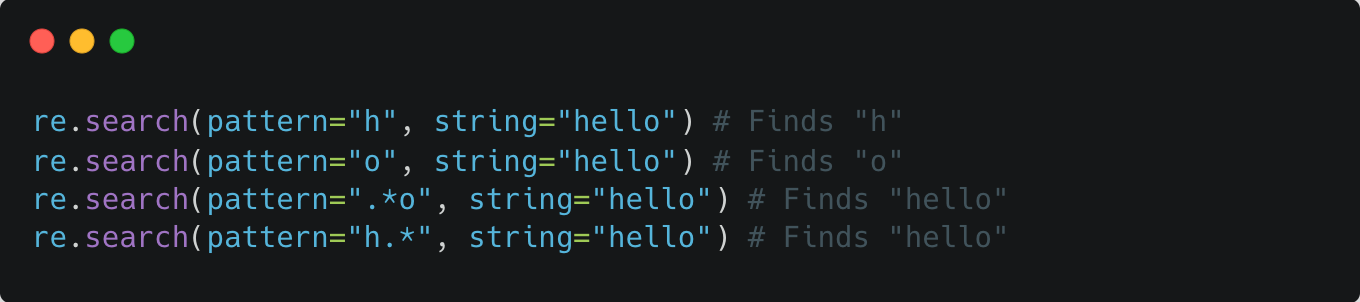
re.subsubstitutes occurrences of a regex pattern found in a string, searches for the pattern like in re.search (returned: string)
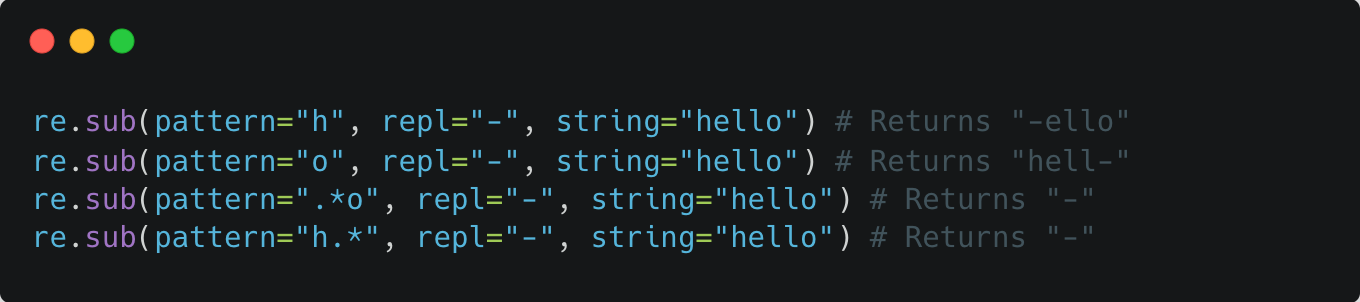
re.findallsearches for all occurrences of a regex pattern in a string, searches for the pattern like in re.search (returned: list of strings)
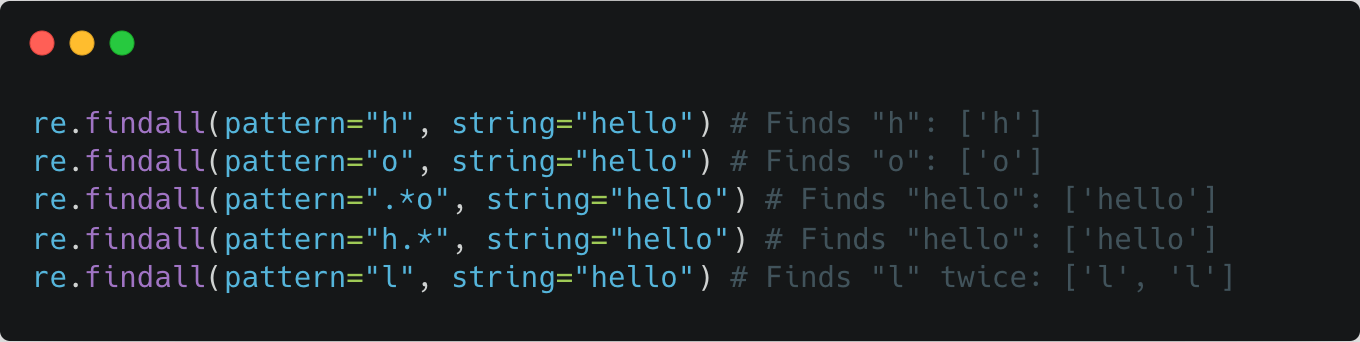
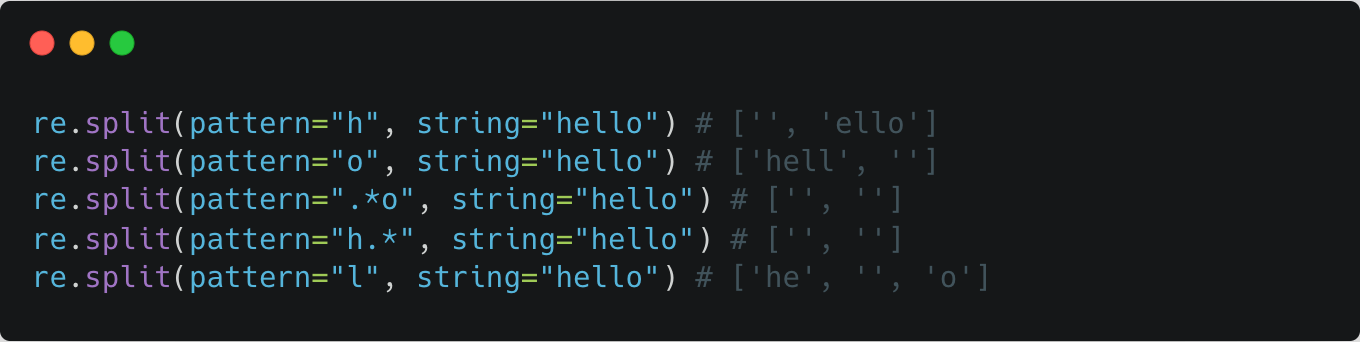
re.splitsplits a string by the occurrences of a regex pattern (returned: list of strings). ❗️note the empty strings returned ❗️
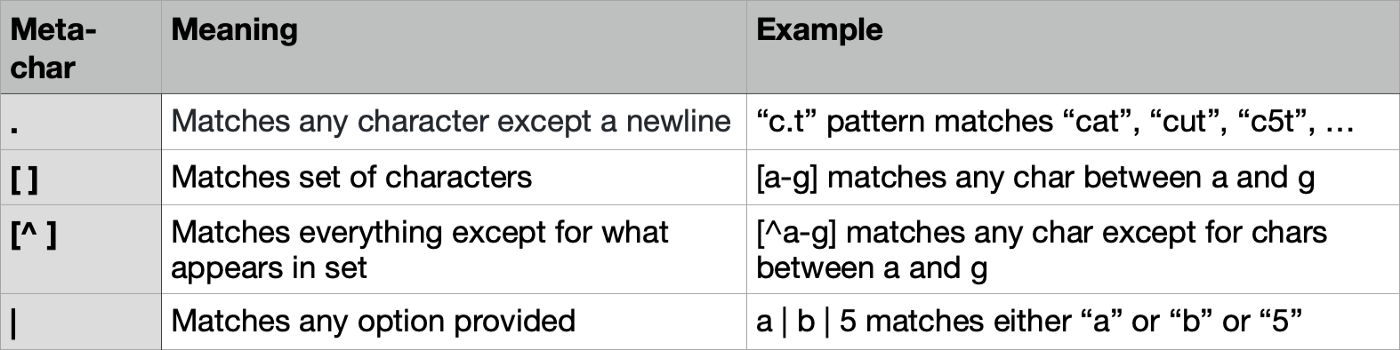
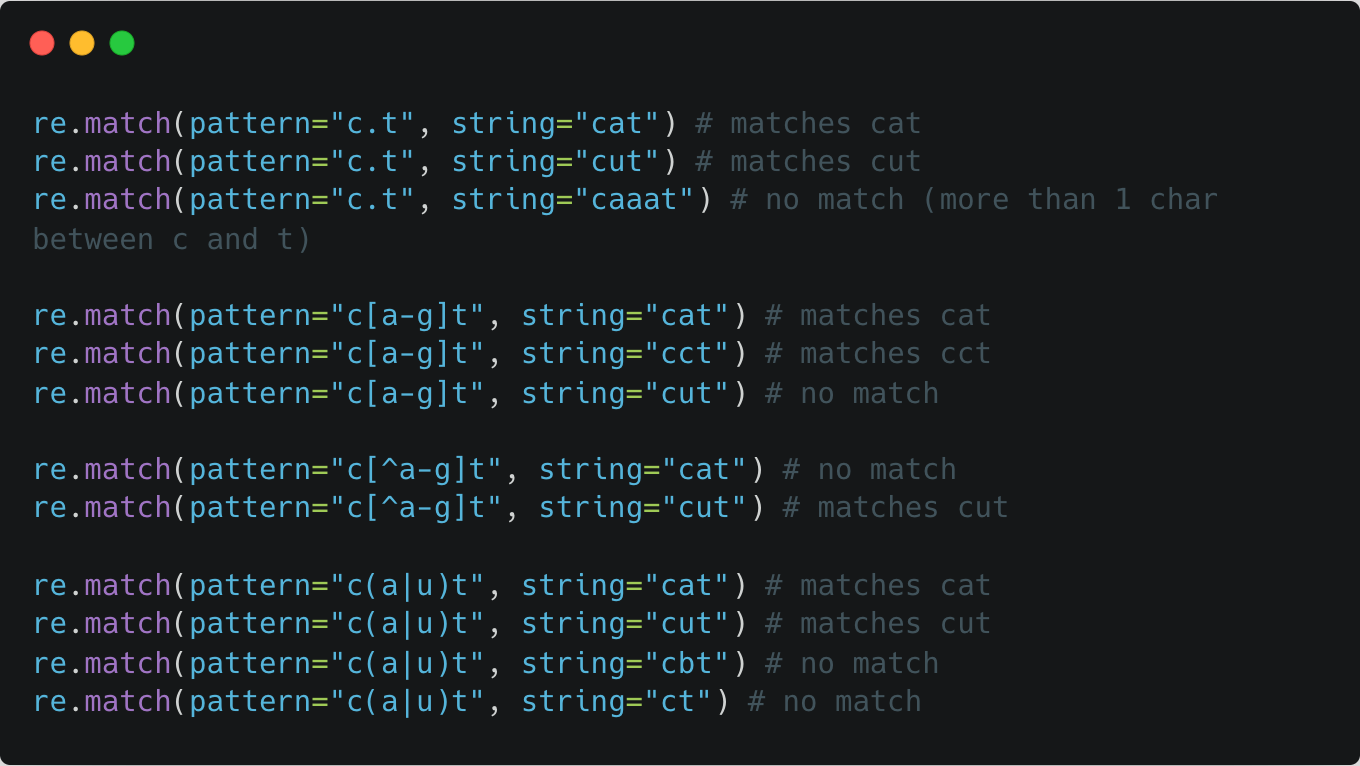
Special meta-characters
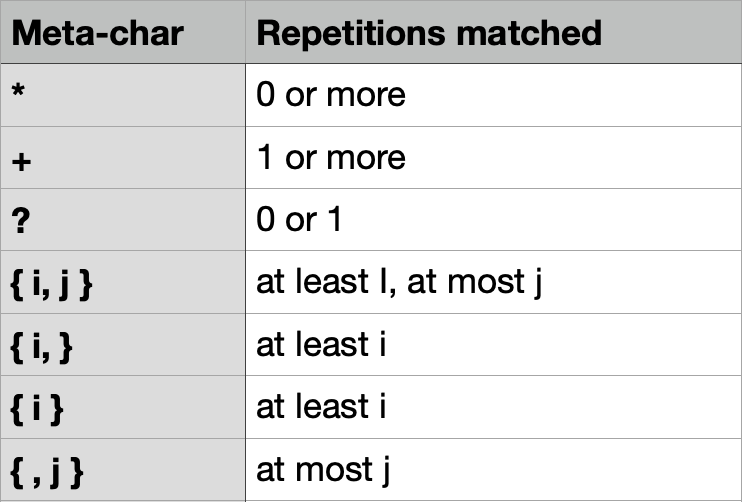
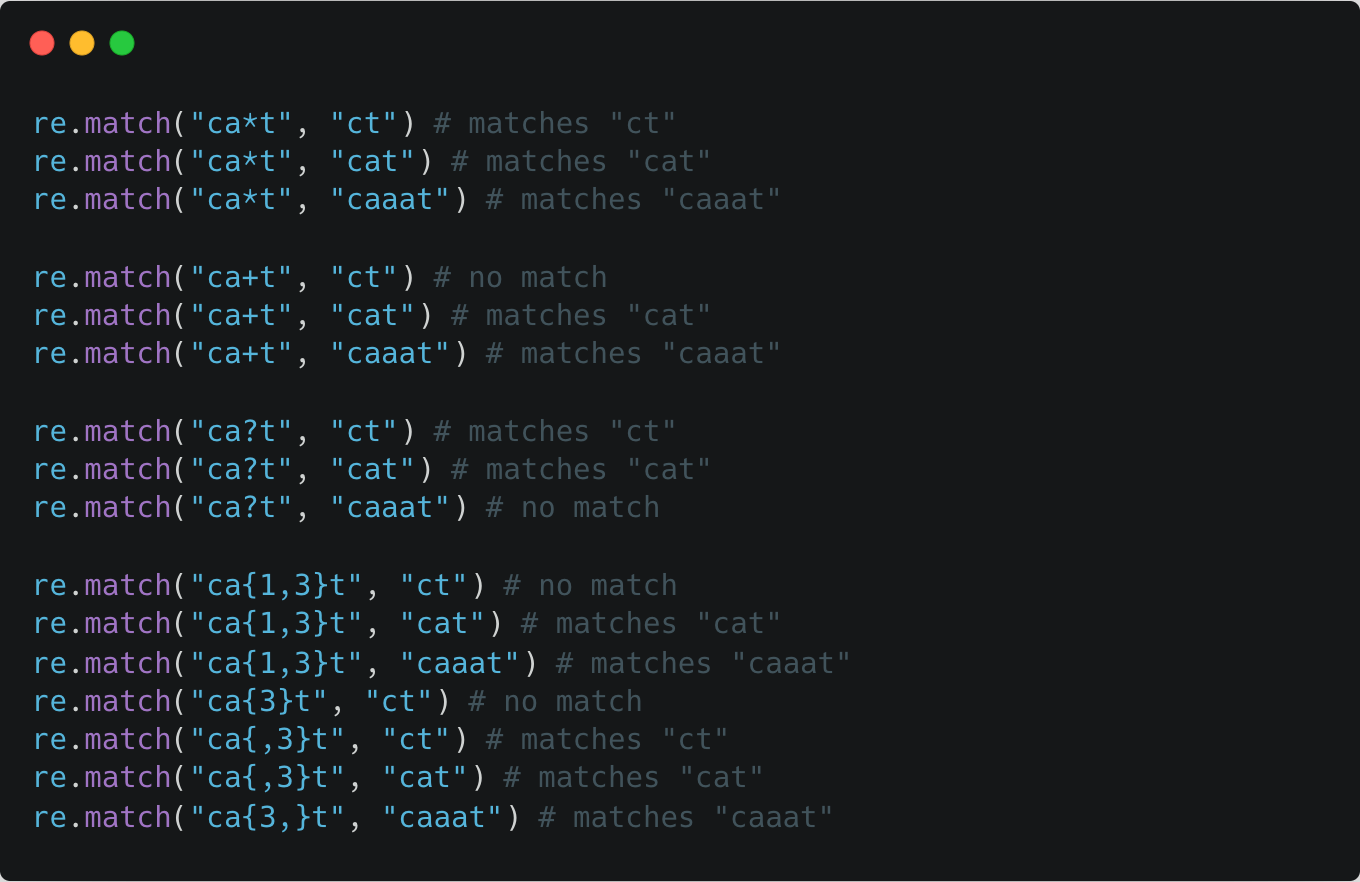
Repetition meta-characters
A table below summarizes the amount of matches of (greedy) repetitions re module performs for the preceding Regular Expression. Greedy means that re module will match as many repetitions as possible.
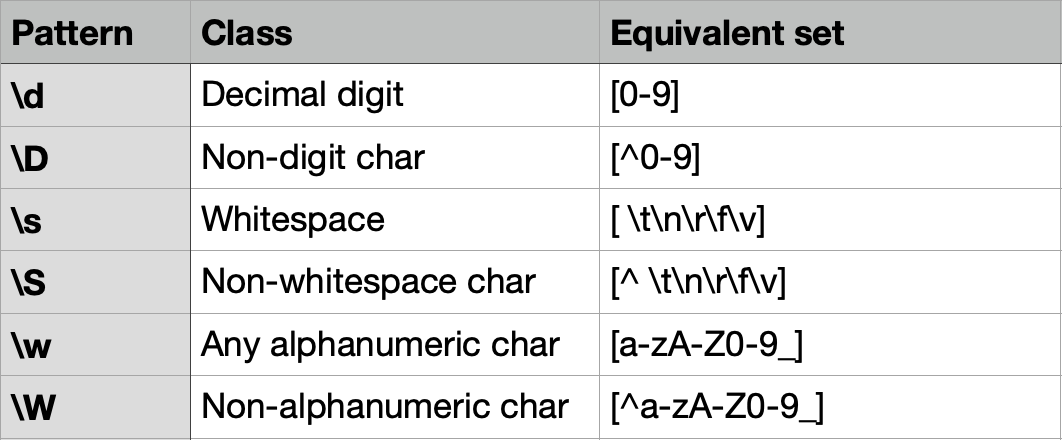
Useful characters classes
Extremely useful tip: grouping and groups extraction
Grouping allows you not only to match text sequences inside strings but also to extract sub-sequences according to groups you define in a pattern.
You can define groups in a pattern by using round brackets — (), and you can extract the groups from the matched sequences by calling group() method on re.Match object.
For example, let’s say we want to match an email in a text, but we also want to easily extract the username, the domain, and the extension out of the email. So if we get the following text: “abc@gmail.com”, we want (1) to detect that this is an email (according to a pattern) and (2) to detect that the username in this email is “abc”, domain name is “gmail”, and the extension in “com”. First, let’s define a simple pattern that will detect this email. Note, I will use a simplified pattern that assumes that there are solely alphanumeric chars in each of the email component, which is not true in a real life, but it will work for our grouping example.

Now, I will add groups to the pattern. Technically, I will just add brackets around different parts of my pattern: username, domain, extension:

We are now ready to match our pattern:

And here comes the magic of groups! We can not only get the matched text, but also extract separate groups by group index as it has been defined in the pattern, just like this:

Nice, ah?
By the way, group(0) will return string that represents the whole match. In our case: “your_name@gmail.com”
Bonus
Sometimes you want to play with all these methods and you need it quick, so we organized them in a Google Colab file which is extremely simple to play with. Just don't forget to run "import re" first at the beggining of the file.
That’s all for now, folks. Happy coding!




